In a nutshell: an encoded polyline is a set of coordinate pairs (of a line or shape) which have been converted to an ASCII string to significantly reduce the overall size of the data. Now that we have a gist of what we\’re talking about, let’s go into some detail.
Encoded polylines are used to store large sets of coordinate data to project a line or shape on a map, typically a Google Map. The encoded polylines are created from sets of coordinate pairs and are fed through an algorithm. Google has a very technical explanation of how the algorithm works, but most of it is gibberish to me. If you do read through it, you can skip the section on levels, as they were deprecated in Google Maps API v3.
Boiled down, what the algorithm does, is take the difference between two coordinate pairs, does some black magic with binary values, and converts that binary value to ASCII characters. Each ASCII character holds eight bits of data, so the savings adds up.
Let’s try a practical example.
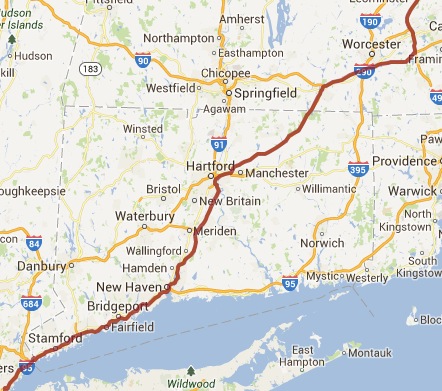
First, we start with a dataset. We’ll use this CSV with 50 coordinate pairs (lat,lon). If you want to play along, you can use Mark McClure’s Encoding Utility. McClure has a bunch of excellent resources on his website including encoded polyline libraries for a bunch of different languages. If we convert the whole dataset, we get:
a`koG`qiiMrwH||R`|Qj_UbpRtuTj|K`aNjhQ~nUzqMzdSpxOzoUx{CpwOliYbwLdrZt_Md}[`zEro\\\\zfDzd\\\\zt@xw\\\\}lBjyQb~JikF~pYryCjqf@fxJ|nb@dyHrte@cjA`xf@siA`xg@uuFzhf@_cB`rg@hjAzkh@fn@hng@nbAzbi@lxAdvT~gB~qZxnD|v\\\\~}VtuFftTlaSnlTrdXrxQxl]zsJxld@jvQne_@`dOnyb@jySrpYndOx__@d`L|r`@~nLtrc@jrCdu`@bxH|bWtmLfw[hlG~tc@f{Hxf^rrKdp\\\\vuPj~WriFptL`cBfiMWe went from 50 coordinate pairs, 1,033 bytes to 327 bytes, a savings of ~70%. It may not seem like a big deal having only 1 kilobyte of data, but this adds up quick when you have big datasets.
One thing to be careful about later on is that there are frequently backslashes in encoded polylines. Depending on what language you’re using, or how you\’re storing the encoded polyline, you may have to escape the escape characters.
But let’s break down the encoded polyline a bit more so we can really understand what is going on. As I mentioned earlier, the polyline algorithm takes the difference between two points and converts it to ASCII. So given the first point in our dataset is 44.626091, -75.092804, the algorithm calculates the offset from the origin (0,0). If we plug in only 44.626091, -75.092804 into the encoding utility, it will give us: a`koG`qiiM. If we look back at the whole encoded polyline, you will see a`koG`qiiM at the beginning. Let’s look at the second point: 44.576079, -75.194874.
To find the next segment of the encoded polyline, we need to find the difference between the first point (44.626091, -75.092804) and the second point (44.576079, -75.194874). After running those points through the encoding utility, we’ll get a`koG`qiiMrwH||R. That string is the difference between 0,0 & 44.626091, -75.092804 and 44.626091, -75.092804 & 44.576079, -75.194874. So to find the second segment of the encoded polyline, we strip the first off the first segment (a`koG`qiiM) which will leave you with rwH||R. Note that the second segment is much shorter than the first. The reason is that the distance between 44.626091, -75.092804 & 44.576079 is much less than the difference between the first point (44.626091, -75.092804) and the origin.
To find the other segments, just keep plugging in the pairs. If you don’t get it, don’t fret too much, it took me a few weeks and a couple of software engineers to fully wrap my head around this. Feel free to leave questions in the comments and I’ll be sure to get back to you.
P.S. Another thing to be cautious of is line endings. When I was playing with some data early on, I exported a CSV from Excel on my Mac which defaults to CR line endings. This was seriously screwing up the algorithm and my points were literally all over the map. To correct this, just open up the CSV in TextWrangler and save as with Unix line endings (LF).
seetha
thak you
Sourav Poddar
Thank . This post was very helpful.
I want to extract co-ordinates of points at regular interval on a google maps route. Is there anyway to do this using the encoded polyline Algorithm.
Dan Mandle
Potentially. Can you retrieve the route as an encoded polyline? If so, you can decode it, and loop through whatever interval you want.
Sourav Poddar
i can retrieve the route as an encoded polyline. I don’t understand the looping through interval part….the source, destination n waypoint co-ordinates are encoded to get the polyline right!? but what if the waypoints are not at regular intervals??
M sorry ….m a rookie at this….first interaction with real world problems so my questions can be a bit stupid…but i really need to understand this. Thank You.
Sourav Poddar
I think i got it….thanks for this article, it was really helpful.
I ll get back to this page if I have any issues regarding this. 🙂
Ramesh Kumar
What you got it? Can you please help me? I am facing similar issue
Luca H.
Thanks for the article. Am I the only one to whom the links for Mark McClure’s articles does not work?
Dan Mandle
Unfortunately McClure’s site has been down for a while. I haven’t found another source of his stuff or anything comparable.